分布式锁实现-DB
在前面我们简单介绍过分布式锁,本篇文章会介绍如果基于数据库(Mysql)实现分布式锁。基于Mysql实现锁的一般场景是对性能要求不高,且不希望因为分布式锁而引入新的组件的。
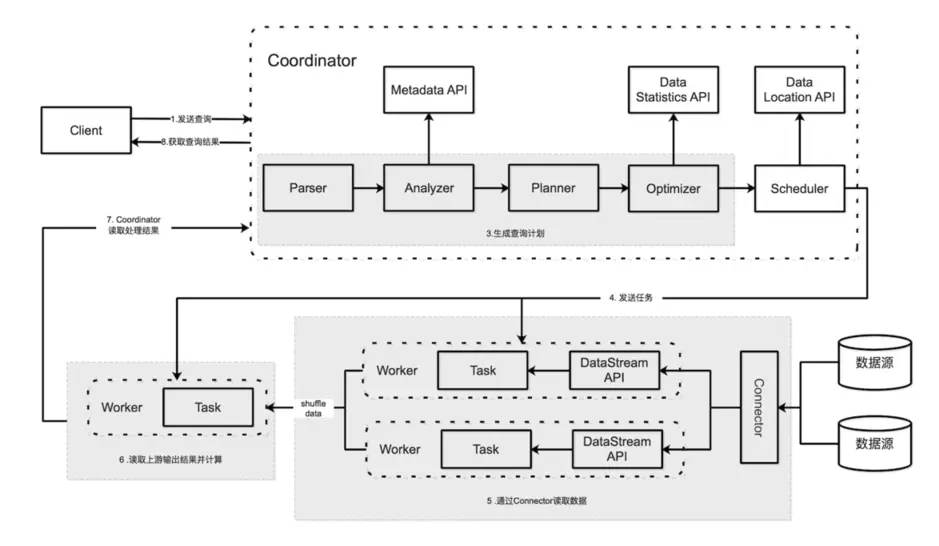
Trino 是一种旨在使用分布式查询高效查询大量数据的工具。通常用在数据仓储、数据分析、海量数据聚合和报表生成等任务上,这些任务通常被归类为联机分析处理(online analytical processing,OLAP)。
通过支持不同系统上的联邦查询、并行查询和横向集群扩展等功能,Trino解决了上述问题。
本文是学习Trino源码前的准备工作。在开始之前,先做好准备工作:
最近在做SQL方面的工作,主要是SQL语法解析和改写。因此打算记录下解析的技术&工具。
文本解析一般首推使用正则表达式。对于大多数的文本,正则都可以很好的解析。以ELK套件中的Logstash为例,其内置的Grok插件支持了120+种常用Pattern,可以很好的用于解析多种形式的文本。但是。正则不是文本解析的万能钥匙,由于正则表达式的自身实现约束,大多数正则表达式引擎不能较好的处理嵌套结构的数据。此外,对于脚本语言或编程语言,正则表达式也是无能为力。
举个例子,如果想替换SQL中的某个字段名,如果只是简单的使用正则替换,那么很可能会错误修改其他位置的文本。例如想修改下面SQL中的order_cnt别名时,就很有可能错误修改其他位置的order_cnt,要避免这类问题需要对正则添加很多断言和约束,由于实际场景中可能会对SQL的列名,表名,条件等各个位置进行改写,场景十分复杂。所以正则这种方式不能从根本上解决问题。由此,引出了接下来要介绍的技术–语法解析器(Parser)。
1 | select |
LFU(Least Frequently Used)最近最少使用算法。它是基于“如果一个数据在最近一段时间内使用次数很少,那么在将来一段时间内被使用的可能性也很小”的思路。
举个例子,缓存空间大小为3:
Maven依赖传递是Maven的核心机制之一,它能够一定程度上简化Maven的依赖配置。
flowchart LR
A -->|depend on|B
B -->|depend on|C
A -->|depend on|C如上图所示,模块A依赖模块B,模块B依赖模块C。此时B是A的直接依赖,C是A的间接依赖。
Maven的依赖传递机制是指,不管Maven项目存在多少间接依赖,POM中都只需要定义其直接依赖,而不需要定义任何间接依赖。Maven 会动读取当前项目各个直接依赖的 POM,将那些必要的间接依赖以传递性依赖的形式引入到当前项目中。Maven 的依赖传递机制能够帮助用户一定程度上简化POM的配置。
基于 A、B、C 三者的依赖关系,根据 Maven 的依赖传递机制,我们只需要在模块 A 的 POM 中定义其直接依赖 B,在模块 B 的 POM 中定义其直接依赖 C,Maven会解析A的直接依赖 B 的POM,将间接依赖 C 以传递性依赖的形式引入到模块 A 中。通过这种依赖传递关系,可以使依赖关系树迅速增长到一个很大的量级,很有可能会出现依赖重复,依赖冲突等情况,Maven 针对这些情况提供了如下功能进行处理:
clickhouse 在查询中使用别名时可能会有下面的问题1。
1 | $ SELECT avg(number) AS number, max(number) FROM numbers(10) |
If aliased expression contains aggregate function, alias should not be resolved inside another aggregate function.
If alias name clashes with the column name, the substitution of this alias should be cancelled.
原因是clickhouse的别名如果和某个列名相同,就会有上面的异常。可以通过添加下面了配置处理上述问题2.
1 | SELECT avg(number) AS number, max(number) FROM numbers(10) |
但是这个配置引入了新的问题3.
Prefer alias for ORDER BY after GROUP BY in case of set prefer_column_name_to_alias=1;
Clickhouse version 21.6
1 | $ SELECT |
clickhouse 社区又提出了新的pr4处理上述问题:
Add more options to prefer_column_name_to_alias setting. This is for #24237
- set prefer_column_name_to_alias=1 --> prefer column over alias in all sub clauses;
- set prefer_column_name_to_alias=2 --> prefer column over alias in all sub clauses before and include group by;
- set prefer_column_name_to_alias=3 --> prefer column over alias in all sub clauses before group by;
Cross-Site Scripting(跨站脚本攻击)简称 XSS,是一种代码注入攻击。攻击者通过在目标网站上注入恶意脚本,使之在用户的浏览器上运行。利用这些恶意脚本,攻击者可获取用户的敏感信息如 Cookie、SessionID 等,进而危害数据安全。为了和 CSS 区分,这里把攻击的第一个字母改成了 X,于是叫做 XSS。XSS 的本质是:恶意代码未经过滤,与网站正常的代码混在一起;浏览器无法分辨哪些脚本是可信的,导致恶意脚本被执行。
而由于直接在用户的终端执行,恶意代码能够直接获取用户的信息,或者利用这些信息冒充用户向网站发起攻击者定义的请求。在部分情况下,由于输入的限制,注入的恶意脚本比较短。但可以通过引入外部的脚本,并由浏览器执行,来完成比较复杂的攻击策略。
在排查线上问题的时候,发现日志中只有java.lang.NullPointerException: null,没有打印出日志堆栈。第一反应是log.error()用错了方法。
1 | void error(String msg); |
在打印异常的时候建议使用 void error(String msg, Throwable t)这个方法。
如果想使用void error(String format, Object... arguments)这个方法,需要注意2点:
1 | String s = "Hello world"; |
仔细检查了代码,发现并不是这个问题引起的。
在使用antlr生成的语法解析器处理多个文件后,JVM 最终会产生内存不足异常,PredictionContextCache中的hashMap和DFA数组_decisionToDFA会不断增长。因为 PredictionContextCache和_decisionToDFA在生成Parser和Lexer中是类共享的。
1 | public class XXXParser extends Parser { |